Why do we care? Because sometimes data come from different sources that we need to aggregate. Let’s see how to make it work.
Good Morning Guys,
Today I am here to present you two special tools to create our personalized and comprehensive dataset. As there are two directions, up and down, so there are two ways to combine a dataset, vertically and horizontally.
Adding Observations
The easiest one is to combine two different datasets vertically using the command append. This is extremely useful when we want to add observations from one file to another one. For example, you have data on cars and their models and prices in 1978 in the dataset auto.dta and you want to include also observations for the years 1988 and 1998. As long as the variables are the same in the two datasets and we only need to add observations for the new measures we are interested in vertically, we can use append to combine these data. Usually, the dataset in memory that we want to enlarge with new data is called “Master Data”, whereas the data to combine from is known as “Using Data”.
Before we append the data, we have to create the variable year1978 in the Master dataset (auto.dta) and the variables year1988 and year1998 in the Using dataset (autonew.dta, for example). If you have read my previous posts, you already know how to do that, but let’s revise it:
gen year1978=1978
label variable year1978 “Auto produced in 1978, first year of study”
After having done the same in the Using dataset we can go back to the master data, check that both datasets are in the right directory and type:
sysuse auto.dta
append using “C:\autonew.dta”
save datasetcombined, replace
This add the observation from the file autonew to the data in memory in auto. You can also omit to declare your data is a .dta, Stata recognizes this format by default. I always recommend you to save different files when you manage the data to prepare your final dataset, in order to avoid overwriting, as already said in this post.
Useful Tip: Is it that easy? Well, yes, but we have to take care of something precautionary. If the variables collected in the Master data are not present in the Using data, Stata will automatically assign a missing value to the observations from the Using data. On the contrary, if there are more variables in the Using data than in the Master data, the observations from the Master Dataset will present missing values in them.
Now that we warmed up, let’s do the tough job.
Adding Variables
The horizontal combination, known as merging procedure, is useful when we want to add variables instead of observations. Several observations will appear in both files but in each dataset, we will find different information about them. For example, if we are dealing with a panel data of firms and we have one dataset with the information over the different companies and firms and another dataset on their workers and their socio-economical characteristics, we might want to combine them horizontally. If we have an identifying variable in both files (i.e. company name) we can assign each firm its workers.
Old Syntax
Before Stata12, the merging procedure was easily done in three steps but it was impossible to choose different ways to merge the datasets. I will present here both the old version of the command (still useable) and the new one. Remember that the merge command requires both datasets to be sorted by the identifying variable we want to use to merge before the launch of the command. Let’s make a practical example.
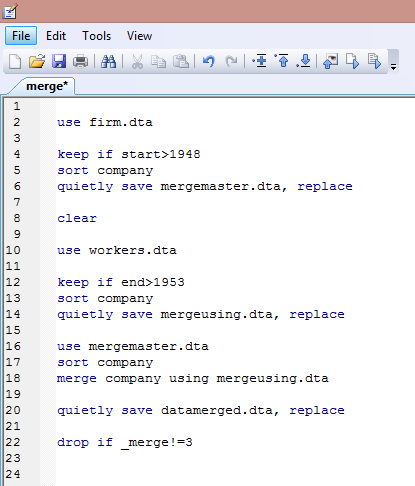
We have a panel data on firms in different countries and we want to combine these data to the survey on workers of those firms conducted in the same time. We want to merge these datasets based on the name of the company. Before this operation, I cleaned the data a bit in order to select a time range and to sort the identifying variable (company). I saved the modified dataset with different names and I used the option quietly that tells Stata not to show the output of the command launched in the Results window. Then, I went back to the sorted master data and I typed:
merge identifying_variable using UsingDataset.dta
Stata recognizes this to be the old version of this command but still implements it. Now, in your dataset, a new variable named _merge is created automatically by the merge command. It takes different values, related to your merging, because it contains information regarding the observation’s existence in each of the two datasets:
- _merge=1 if the values of the identifying variable appears only in the Master,
- _merge=2 If the values of the identifying variable appears only in the Using,
- _merge=3 if the values of the identifying variable appears in both datasets
Depending on the content of your research, you can decide what to do with this information. In our example we have firms data in the Master Data but we might be interested in individuals (in the Using data) working at these firms, thus we do not need observations with firm data but without workers linked to them, thus we can decide to get rid of them if _merge=1 by simply drop them off. There are two ways to do this:
After the merge command: drop if _merge==1
Before the merge command: option nokeep; merge company using “C:\mergeusing.dta”, nokeep
Can we merge more than one file with only one command?
The answer is straightforward, Yes. But, I personally disagree to do that. Having an iteratively procedure allows you to check everything is working step-by-step but it can be noisy because you have to drop the variable _merge each time. Otherwise use the merge command adding more dataset after using like:
merge company using mergeusing.dta auto.dta productivity.dta, nokeep
This command will create different merging variables that are dummies: _merge1, _merge2, _merge3 and so on. The _merge variable, the comprehensive measure, will be still there but its interpretation is now different. It will takes value 3 if and only if the observations appeared in at least one of the using datasets.
What you have to know: Another useful way is to construct a LOOP. This tool is one of the biggest nightmares of Stata users until they do not understand the logic behind it. I will create a post dedicated to this command but I reveal in advance that it can be used to merge several datasets. You only must be sure that all the datasets you want to merge are in the same directory and are coded similarly. For example, I want to combine datasets on Italian, Spanish, Greek and French GDP for the year 2014. I rename the datasets as I1,S1,G1,F1 and I write:
Use I1.dta
foreach country in S G F{
append using ‘country’1.dta
}
As I said before: Don’t Panic! I will come back on loop and macros in a new post!
New Syntax
Since Stata11 a new procedure can be used to merge two datasets. If you type help merge, a new window will open up:

Let’s present all these specifications!
-
One-to-One merge
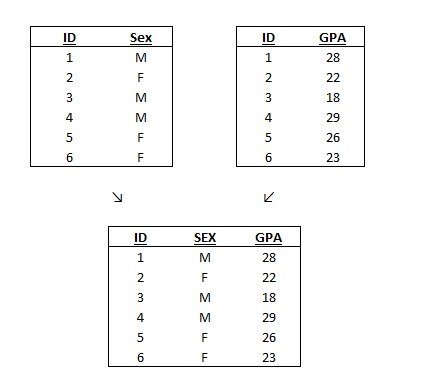
Let’s make a different example. We have a dataset named student.dta and another one with their university GPA called grade.dta. A different ID number (to preserve privacy) identifies each student. The identifying variable (ID) appears uniquely in both datasets. Thus, this is considered a one-to-one match because for each value of this variable there is only one observation that contains it. In our example, each student has only one sex and one GPA.
-
One-to-Many Merge
This merging method is extremely useful if the identifying variable is unique in one dataset but not in the other one. This is common when you have two ways of grouping observations in the different dataset. For example, let us use again the file student.dta and try to merge it with the file household.dta. Now, individuals are related to different household and we can group students to households because the variable HH is common to both datasets. We must be aware that the variable HH is unique in the household.dta file but not in the student.dta one. This merging enables Stata to assign the same income value of the household to different member of the same family. The unique identifier of the students (ID) is irrelevant in this case because the merge is performed using the household identifier (HH).
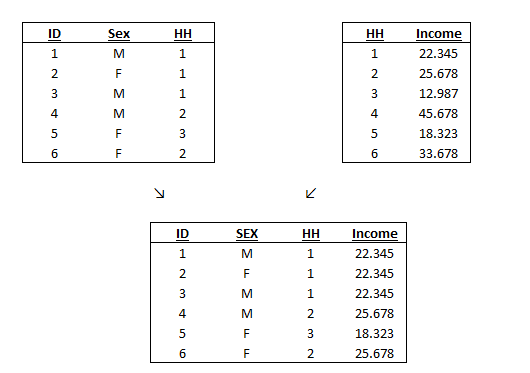
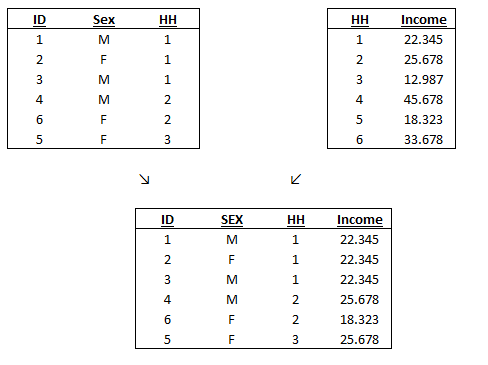
A graphical example is the best way to understand how this merge procedure works. One-to-many means that in the Master (or Using) Data there is a variable that takes mutually exclusive different values whereas in the other dataset this variable is repeated. In this case, I sorted the merged dataset for ID, if you prefer to sort it for Household just type: sort HH and your data will appear like that:
-
Many-to-many merge
This merging method is extremely rare and difficult to perform. You have to be careful and understand what the logic behind your dataset’s construction is. For a m:m merge to work the order of the observations with matching ID across data sets matters. A m:m merge will merge the first observation in the Master data to the first matching observation in Using data. It will continue to do this until it runs out of observations in one data set or the other. M:m merge might work with some examples but is not actually a good idea. In order to perform it, you basically need two datasets that have multiple lines per observation that are always ordered in exactly the order you want to match them in. That setup will work with a m:m merge as long as you don’t do anything else to the data before merging. However, I wouldn’t go for m:m merging when I can open my data and create a variable recording the original observation order within the identifier to avoid screwing things up later by resorting. Then I would just do a 1:1 merge using the original id and the created ordered variable.
FINISHED? Of course, Not.
There is another command that works almost in the same manner as merge, joinby.
Its main difference with merge arises when you’re dealing with many-to-many matches, but it can be used for one-to-one and one-to-many matches too. The simple syntax is:
joinby identifying_variable using “C::\data.dta”
Unlike merge, there is no need to sort the data by the identifying variables, which is an advantage. The disadvantage is that, by default, joinby drops all the observations that do not appear in both datasets. If you want to keep them, you must use the unmatched() option. This option has three possible variations:
- unmatched(master) – Keep observations in Master Data that have no match in Using Data (but not vice versa)
- unmatched(using) – Keep observations from Using Data that have no match in Master Data (but not vice versa)
- unmatched(both) – Keep all unmatched observations, from both Using and Master Data
Insights
As any trustworthy command, merge as options that can really help you out in different cases. The only one I want to spend some words on is update. This option is extremely useful if you have some overlap between the variables in your datasets. If you are analyzing the Years of Schooling(YoS) of families in Italy and France and you want to merge those data you are expecting to have YoS in both datasets. If you do not specify to Stata which values should be used when merging, by default, values of the Master data are kept. If you use the option update replace instead, Stata will take the values from the Using data and replace them to those of the Master Data. If you use update alone (without replace), however, Stata will put the Using Data values only in observations where the Master Data values are missing. So in case you have the same variable but different values, use neither option when you think the Master Data is more reliable. Use the update replace options if you think the Using Data is more reliable. If they are equally reliable, use just update. This option is also available for joinby.